Déploiement continu, par quoi commencer ?
02 May 2014Le mouvement Lean Startup nous apprend à réduire les gaspillages quand on veut innover. Cette démarche est basée sur des cycles courts où se succèdent réalisations, mesures et apprentissages. Elle est constituée de plusieurs pratiques qui facilitent la mise en place de ces cycles. La pratique que je trouve la plus intéressante c’est le déploiement continu qui permet de déployer du code en production plusieurs fois par jour. Vous trouverez ici tous les éléments pour la démarrer au mieux. Cet article reprend les conseils du livre « Running Lean»[1].
La figure ci dessous représente la vue générale du cycle de déploiement continu :
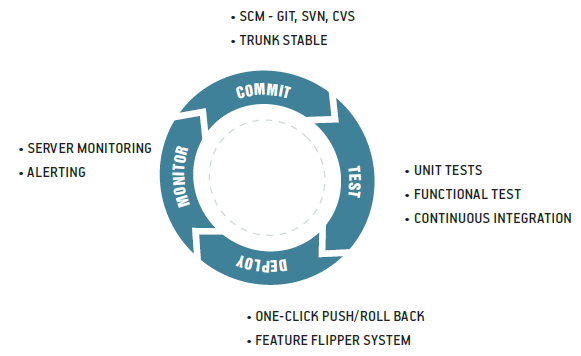
C’est ce que nous allons détailler dans la suite de cet article.
Une bonne manière de réduire le gaspillage c’est de réduire le volume de travail en cours (i.e. le code non déployé). En effet, avoir beaucoup de code non déployé augmente votre inertie et réduit votre capacité à réagir rapidement car il y a plus d’intégration, plus de coordination et plus de planning à faire.
Voici deux techniques qui vous aideront à réduire le volume de code non déployé :
-
Livrez le code en petits lots.
L’idée ici c’est de déployer moins de code mais de manière plus fréquente. Définir ce qu’est un petit lot est assez relatif, mais efforcez-vous de le faire aussi petit que possible. J’ai eu pour habitude de déployer du code deux fois par semaine avec mon dernier produit et finalement j’ai réduit la taille d’un lot à une session de deux heures de code. Evidemment, vous ne finirez pas une fonctionnalité complète en deux heures, mais vous deviendrez bon à écrire et déployer du code de manière incrémentale. Le nombre de lignes de code de mon lot moyen est passé de quelques centaines de lignes à environ 25 lignes. Un des effets direct d’un déploiement d’à peine 25 lignes plutôt qu’une centaine c’est que, immédiatement après un déploiement, le diagnostic des problèmes de production devient beaucoup plus facile, de même que la correction et la re-livraison.
-
Gardez stable la branche principale.
Une autre pratique pour réduire le stock de travail en cours c’est de ne pas utiliser de branches dans l’arbre de votre gestionnaire de code source. Je sais que ça semble un peu extrême parce que créer des branches et les fusionner font partie des fonctionnalités mises en avant dans un système de gestion du code source. Ils vous permettent d’isoler les gros changements risqués de la branche principale qui elle reste stable. Mais plus vous restez éloigner longtemps de la branche principale, plus vous collectez de la dette d’intégration. Ce qui inévitablement conduit encore à plus de risques d’intégration, de coordination et de planification. Il est plus efficace d’avoir un tronc stable puis construire et déployer vos fonctionnalités de façon incrémentale. C’est important de souligner que déployer des fonctionnalités de façon incrémentale ne signifie pas nécessairement qu’elles sont disponibles tout de suite par tous les utilisateurs. Cela vous permet de déployer de manière incrémentale des grosses fonctionnalités et de les rendre disponibles à des utilisateurs sélectionnés (comme votre équipe interne) jusqu’à ce que vous soyez prêt à les lancer. Je couvrirai l’utilisation du système de basculement des fonctionnalités (« feature flipping ») dans la section déploiement.
#Testez
Plonger dans le déploiement continu est particulièrement effrayant parce qu’il élimine les tests manuels (les tests de QA : Quality Assurance ou Assurance Qualité en français). Ces tests servent typiquement de filet de sécurité pour identifier les défauts après le développement et avant le déploiement en production.
Voici quelques lignes directrices pour surmonter cette peur :
-
Le test est la responsabilité de chacun.
Premièrement, il n’y a pas de startup de 2 ou 3 personnes qui ont un département QA, ce qui par conséquent rend le test la responsabilité de chacun. Deuxièmement, un long cycle de test crée les mêmes problèmes de stock de code non livré dont nous avons parlé plus haut. La solution n’est donc pas de créer un département QA séparé, mais de l’inclure dans le processus de développement et d’investir plus lourdement dans les tests automatiques.
-
Utilisez un serveur d’intégration continue.
Mettez en place un serveur d’intégration continue comme Hudson. Il déclenchera automatiquement un “build” (si vous avez du code compilé) et démarrera les tests de l’application après chaque « commit ».
-
Ne tolérez aucun test en échec.
J’ai travaillé à des endroits où les développeurs ignoraient les tests en échec parce qu’ils savaient qu’ils n’étaient plus à jour. Dans un système de déploiement continu, ces tests sont votre dernière ligne de défense avant de pousser le code en production. Vous ne pouvez donc pas tolérer un seul test en échec, en particulier parce que votre but ultime est d’automatiser le déploiement.
-
Préférez les tests fonctionnels aux tests unitaires.
Je ne recommande pas de réaliser “une couverture complète par les tests”. Au contraire, je crois qu’écrire des tests unitaires pour des cas-limites obscurs est une forme de gaspillage. Réaliser une couverture complète n’est pas non plus une utilisation optimale du temps quand il faut se concentrer sur la vitesse et l’apprentissage. Je préfère créer des tests fonctionnels plutôt que des tests unitaires quand c’est possible. Il y a plusieurs bons outils, comme Selenium et Sauce Labs par exemple, qui permettent d’écrire et automatiser des tests fonctionnels pour les applications Web.
-
Commencez par votre flux d’activation.
Ecrire des tests pour des fonctionnalités que votre client ne verra jamais est aussi une forme de gaspillage. Quand vous écrivez des tests, utilisez le cycle de vie de votre client pour « prioriser » vos tests. Démarrez avec le flux d’activation puis de façon incrémentale ajoutez d’autres tests fonctionnels au fil du temps.
#Déployez
L’étape de déploiement consiste à déposer du code testé dans l’environnement de production. Comme cela peut devenir très compliqué quand vous avez plusieurs dizaines de machines, il est mieux de le faire dès le début, quand vous avez juste quelques serveurs.
-
Externalisez autant que possible votre infrastructure.
Le fait de dépenser de l’énergie à mettre en place et configurer vos propres serveurs quand vous vous lancez est une forme de gaspillage. Vous devriez plutôt choisir un fournisseur de plateforme « Cloud » (comme Amazon ou Heroku) et concentrer tous vos efforts sur la construction de votre application et pas votre infrastructure. Sachez que beaucoup de fournisseurs « Cloud » offrent des niveaux gratuits pour démarrer.
-
Créez une zone de préproduction seulement si vous y êtes enclin.
Une zone de préproduction (« staging ») séparée est un filet de sécurité supplémentaire avant de pousser votre code en production. Ca peut être une bonne idée pour gagner en confiance dans votre système de déploiement. Toutefois, j’ai trouvé les zones de « staging » d’une utilité limitée au-delà de la vérification des points de base. Votre serveur d’intégration continue doit être capable de tenir cette fonction de façon répétable et automatisée.
-
Construire des scripts de « push » et « rollback » en un click.
La prochaine étape consiste à écrire un ensemble de scripts de déploiement qui peuvent pousser votre code sur votre serveur de production ou remettre le code de votre dernière livraison. Ce « rollback » est utilisé au cas où vous pousseriez un mauvais changement. Si vous déployez des lots assez petits, vous ne devriez avoir besoin de revenir au-delà de la dernière livraison. Si vous êtes sur Heroku, « push » et « rollback » en un click sont offerts.
-
Déployez à main d’abord puis automatisez.
C’est généralement une bonne idée d’exécuter le script de déploiement à la main d’abord et auditer chaque déploiement le temps de gagner en confiance. Si vous utilisez Hudson comme votre outil d’intégration continue, il est assez facile par la suite d’ajouter une tâche pour déclencher automatiquement votre script de déploiement quand vous êtes prêt pour ça.
-
Implémenter un système simple de bascule de fonctionnalité.
Vous allez inévitablement faire face au déploiement d’une nouvelle « grosse » fonctionnalité tout en maintenant les anciennes. Vous aurez besoin d’avoir un mécanisme en place pour isoler les utilisateurs de ces changements. Un système de bascule des fonctionnalités (« feature flipping ») utilise des flags dans votre code. Ils vous permettent d’activer/désactiver les fonctionnalités par utilisateur.
-
Surveillez (« Monitorez »).
Votre système de surveillance doit vous permettre de détecter une panne, d’alerter les personnes concernées ou parfois de remettre automatiquement le système en état. Un exemple de recouvrement pourrait être d’automatiquement déclencher un script de retour arrière (« roll-back ») dans le cas d’une livraison vérolée. Pour être capable de le faire, votre système de surveillance devra être assez sophistiqué pour surveiller la santé de votre serveur mais aussi la santé de votre application (avec des métriques métiers). La bonne nouvelle c’est que vous n’avez pas à faire ça tout de suite. C’est en fait une forme de gaspillage que d’essayer de « sur-construire » son système de monitoring Le cycle de déploiement continu possède les boucles de « feedback » qui vous aideront à construire ce monitoring de manière incrémentale. Voici comment faire : Démarrez avec un système de surveillance vendu sur étagère Il y a de nombreuses applications de « monitoring » et d’ « alerting » vendues sur étagère comme Ganglia, Nagios ou New Relic. Vous pouvez les utiliser pour démarrer la surveillance de la santé de votre serveur.
-
Tolérez les problèmes seulement une fois.
Chaque fois que vous avez un problème inattendu, analysez-en la cause racine et implémentez une solution dans votre système de monitoring. Pour identifier une cause racine, appliquez la règle des Cinq Pourquoi. Cette règle est basée sur des questions pour explorer le lien de cause à effet d’un problème particulier.
L’exemple suivant démontre le processus de base (Source Wikipédia) :
- Ma voiture ne démarre pas
- Pourquoi ? La batterie est morte (premier pourquoi)
- Pourquoi ? L’alternateur ne fonctionne pas (2ème pourquoi)
- Pourquoi ? La courroie de l’alternateur est cassée (3ème pourquoi)
- Pourquoi ? La courroie de l’alternateur a été bien au-delà de sa durée de vie utile et n’a jamais été remplacée (4ème pourquoi)
- Pourquoi ? Je n’ai pas fait entretenir ma voiture en accord avec les recommandations du constructeur (5ème pourquoi, une cause racine)
- Pourquoi ? Les pièces de rechange ne sont pas disponibles à cause de l’âge très ancien de mon véhicule (6ème pourquoi, note de bas de page optionnelle)
Je vais donc commencer à faire entretenir ma voiture en accord avec les recommandations du constructeur.
Appliquée aux problèmes inattendus dans votre environnement de production, chaque analyse des Cinq Pourquoi doit donner en résultat une série de tests, de sondes et d’alertes que vous aller ajouter à votre système.